

Claude 4 fine-tuning and customization techniques are rapidly becoming essential tools for developers, product managers, and AI engineers who want to move beyond generic responses. Whether you’re building internal tools, domain-specific assistants, or complex enterprise workflows, adapting Claude 4 to your context can yield dramatically better results.
This guide breaks down the three most practical approaches to customizing Claude 4: prompt engineering, fine-tuning (in the broader sense), and retrieval-augmented generation (RAG). These aren’t just theoretical ideas they’re patterns that already power some of the most reliable AI-based tools in production.
Table of Contents
Customizing Claude 4 Fine-Tuning, Prompt Engineering, and RAG Explained
When Claude 4’s default behavior isn’t enough, tailoring it to your data and intent becomes crucial. Unlike traditional fine-tuning that requires retraining weights, Claude 4 offers more flexible, safer ways to specialize behavior: advanced prompt structuring and RAG pipelines. With these methods, you can shape responses, control tone, inject knowledge, and reduce hallucination all without touching the core model.
Let’s break it down. If you’re new to Claude’s architecture, read our Claude 4 by Anthropic article first to understand its foundational approach to alignment and safety.
Fine-Tuning Claude 4 What’s Possible, What’s Not
While you can’t fine-tune Claude 4 in the traditional open-weight sense like some open-source LLMs, you can simulate fine-tuning with techniques like in-context learning, system prompts, and template chaining. This approach is often called “soft fine-tuning.”
What Claude 4 allows:
- You can embed structured documents, tone conditioning, and behavioral rules in the system prompt.
- You can simulate memory using hidden context blocks and prior user history.
- You can align Claude’s responses by injecting domain-specific guidelines.
Limitations:
- You can’t train new weights directly (Anthropic does not expose the model weights).
- Persistent memory isn’t native yet, though long context helps.
Example: A legal team “fine-tunes” Claude by giving it a rich context document describing regional compliance laws and embedding this into every session. The result? Claude outputs summaries and answers using correct legal terminology 90%+ of the time.
Prompt Engineering Techniques That Actually Work
Prompt engineering is still your most powerful customization tool. Done right, it turns Claude into a domain-savvy assistant. Done wrong, it leads to vague answers or hallucination.
Core techniques:
- Role prompting: Define Claude’s voice, authority, and tone. (e.g., “You are a compliance advisor for U.S. healthcare policy.”)
- System prompt scaffolding: Embed structured guides, decision trees, or templates.
- Input-output pairing: Use sample questions and expected answers to teach form.
Examples of well-engineered prompts:
- “List the top 3 regulatory risks for fintech startups operating in California. Respond with bullet points and cite sources.”
- “Rewrite this technical abstract into plain English for a non-specialist audience.”
Prompt engineering is especially effective when paired with Claude’s ultra-large context window (~200K tokens), as detailed in our Claude 4 for Writers article where structured tone and idea generation play a major role in output quality., allowing you to feed detailed background before the question even begins.
Implementing RAG with Claude 4 for Better Answers
Retrieval-Augmented Generation (RAG) solves one of the biggest limitations of LLMs: their static training data. With RAG, you dynamically inject up-to-date, context-rich documents into each prompt. Meta AI’s breakdown of RAG explains how it works in production systems.
What is RAG?
It’s a method where a search/retrieval layer (e.g., Pinecone, Weaviate, FAISS) pulls the most relevant data based on a query. That data is then embedded into the Claude prompt to generate a more accurate and grounded response.
Claude 4 in a RAG pipeline:
- Step 1: User asks question (“What’s our latest product spec for Q3?”)
- Step 2: Vector search retrieves relevant PDF snippets or database entries.
- Step 3: Claude receives the prompt + retrieved content, and answers accurately.
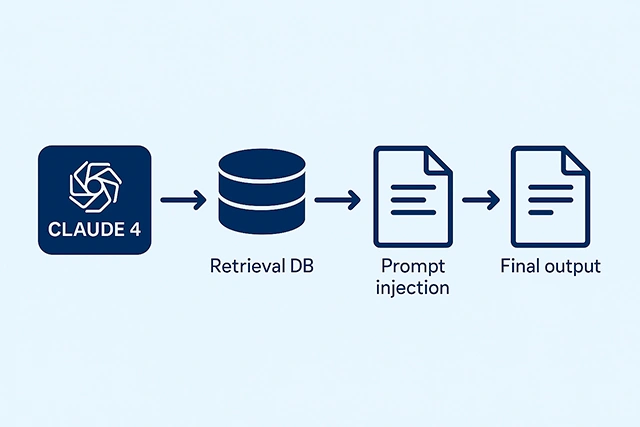
Why Claude excels in RAG:
- Handles large document chunks due to 200K context window.
- Safer output fewer hallucinations.
- Ideal for customer support, document QA, and enterprise bots.
Claude 4 vs GPT-4 in Customization Use Cases
Both Claude 4 and GPT-4 are strong generalist models, but their tuning philosophies differ. We explored this contrast further in Claude 4 vs GPT-4: A Deep Dive Into Their AI Training Philosophy. Claude 4 uses constitutional AI to guide alignment and tone. GPT-4 leans toward expressive generation and creativity.
When Claude 4 is better:
- You need consistent tone (e.g., legal, policy, corporate tone)
- Tasks requiring grounded document summarization
- Controlled prompt behavior (less risk of jailbreaks)
When GPT-4 might shine:
- You want open-ended creativity (e.g., fiction writing, brainstorming)
- Building tools that rely on dynamic plugin execution
Key difference: Claude’s larger context window makes it a top choice for RAG-heavy systems where hallucination is costly.
Best Practices and Pitfalls to Avoid
If you’re building workflows around Claude, these do’s and don’ts will save you hours:
Do:
- Chunk large documents to <30K tokens per segment
- Preprocess input text (strip noise, simplify formatting)
- Use metadata to steer retrieval (e.g., “doc:spec_sheet, product:X”)
- Cache frequent queries
Don’t:
- Overload Claude with raw dumps (avoid dumping 100-page PDFs)
- Assume prompt order doesn’t matter
- Let user inputs go unfiltered (sanitize before injection)
Prompt Injection Mitigation:
- Don’t allow direct user prompts into system context
- Add guardrails using Claude’s tone + formatting controls
Tools and Frameworks to Supercharge Claude 4
You don’t have to build everything from scratch. These tools work beautifully with Claude, and many of them are already used in Claude 4 API Integration workflows:
- LangChain: Chain Claude prompts, plug into vector stores
- Make.com: Automate Claude workflows (e.g., file in Google Drive → Claude summary → Notion)
- Claude API: Use Claude in microservices or middleware
- Slack + Claude: Build custom agents that respond contextually using message history
Example Project: Use Claude + Pinecone + LangChain to build a legal research bot. The bot reads, retrieves, and responds in real-time, while being safe and cost-efficient.
Final Thoughts – Let Claude Work For You
You don’t need to build your own LLM to get expert-level output. With Claude 4’s advanced prompt engineering capabilities, RAG integration potential, and massive context handling, it’s easier than ever to tailor your assistant to your stack, your tone, and your data.
Whether you’re prototyping an internal tool or deploying a customer-facing app, Claude can become your low-latency, high-compliance, ever-consistent partner.
Still using generic chatbots? It might be time to give Claude something better: your context. And if you’re thinking about scaling this for enterprise use, you might also be interested in Claude 4 for Business Automation.


